Last updated on March 6th, 2025 at 02:14 pm How Music Prompt Search Works & Why It’s Only Part of the Puzzle Alongside our Similarity Search, which...


Articles
Last updated on March 6th, 2025 at 02:14 pm How Music Prompt Search Works & Why It’s Only Part of the Puzzle Alongside our Similarity Search, which...

The Problem The sync licensing industry faces a fundamental information asymmetry problem. With hundreds of production music libraries operating globally,...

Ready to supercharge your discovery workflows? Try out the Advanced Search API. We’re excited to introduce Advanced Search, the biggest upgrade to Similarity...
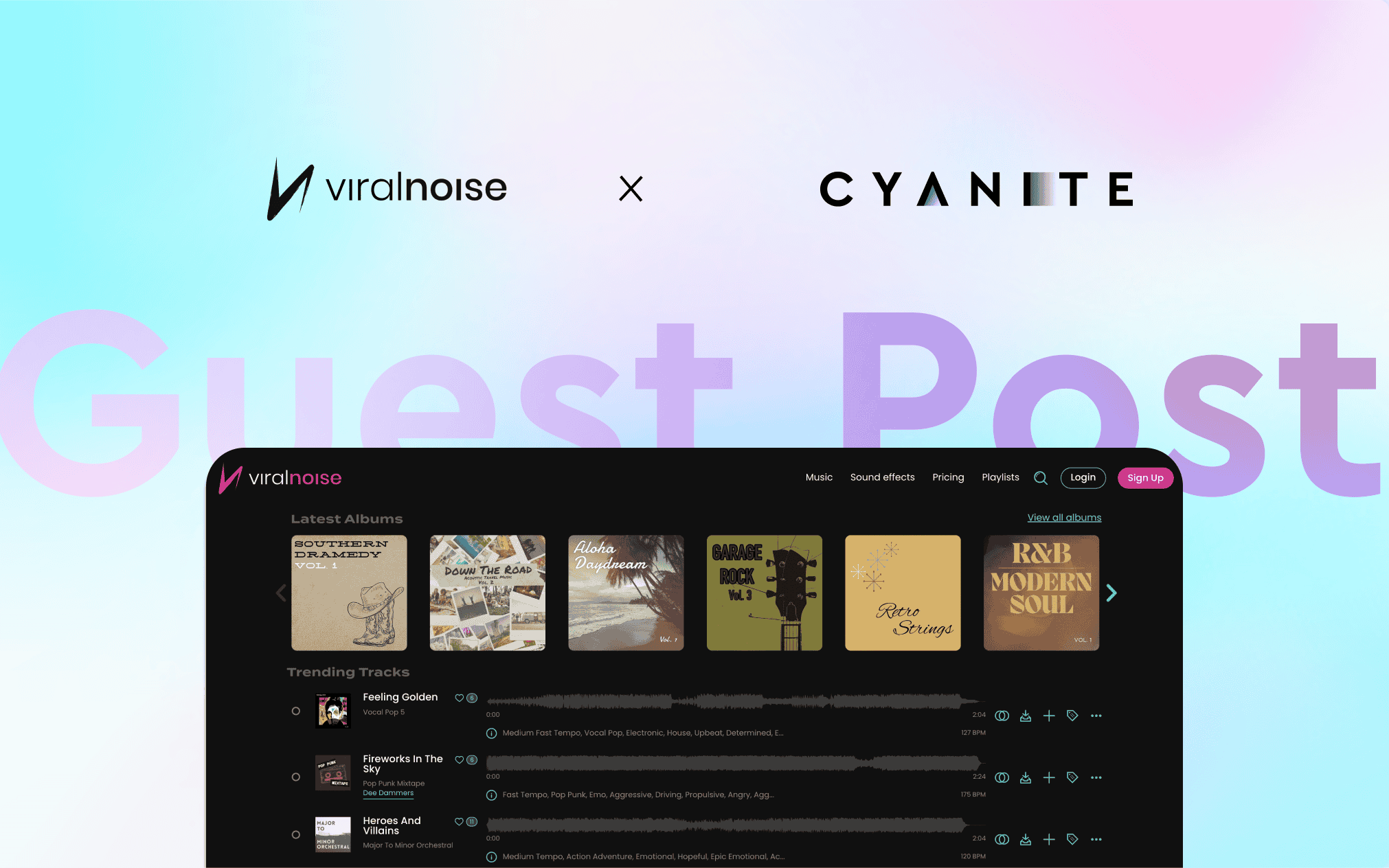
Last updated on March 6th, 2025 at 02:14 pm By Viralnoise - https://www.viralnoise.com/ Finding the perfect track for your content used to mean endless...

In the ever-evolving landscape of sync and music publishing, leveraging advanced technology is essential for staying competitive. Cyanite offers an AI search...

This is part 1 of 2. To dive deeper into the data we analyzed, click here to check out part 2.Gender Bias in AI Music: An Introduction Gender Bias in AI Music...

Part 2 of 2. To get a more general overview of AI Music recommendation fairness - more specifically the topic of gender bias, click here to check out part...

In today's digital age, efficiently managing vast amounts of content is crucial for businesses, especially in the music industry. For those who decide not to...

Ready to boost your catalog with 1,500+ genre tags? Start auto-tagging with Cyanite. We’re thrilled to announce the biggest web app update since its launch....
An Introduction By Jakob Höflich, Co-Founder and CMO of CyaniteWhen I was 19, I worked at community radio 4ZZZ in Brisbane, tasked with digitizing daily CD...

Founded in 2010, Marmoset is a full-service music licensing agency representing hundreds of independent artists and labels. At the heart of it, their core...

Music streaming platform Sonu has partnered with AI-powered music tagging and search company Cyanite to introduce VibeCheck, a fresh feature for listeners to...