Last updated on June 28th, 2023 at 02:34 pm
As written in the earlier blog article, we at Cyanite focus on the analysis of music by using artificial intelligence (AI) in the form of neural networks. Neural networks in music can be utilized for many tasks like automatically detecting the genre or the mood of a song, but sometimes it can also be tricky to understand how they work exactly.
With this article, we want to shed light on how neural networks can be deployed for analyzing music. Therefore, we’ll be guiding you through the four essential steps you need to know when it comes to neural networks and AI audio analysis. To see a music neural network in action, check out one of our data stories, for example, an Analysis of German Club Sounds with Cyanite.
The 4 steps for analyzing music with neural networks include:
1. Collecting data
2. Preprocessing audio data
3. Training the neural network
4. Testing and evaluating the network
Let’s say that we want to automatically detect the genre of a song. That is, the computer should correctly predict whether a certain song is, for example, a Pop, Rock, or Metal song. This seems like a simple task for a human being, but it can be a tough one for a computer. This is where deep learning in the form of neural networks come in handy.
In general, a neural network is an attempt to mimic how the human brain functions. But before the neural network is able to predict the genre of a song, it first needs to learn what a genre is.
Simply put: what makes a Pop song a Pop song? What is the difference between a Pop song and a Metal song? And so on. To accomplish this, the network needs to “see” loads of examples of Pop, Rock or Metal, etc. songs, which is why we need a lot of correctly labeled data.
Labeled data means that the actual audio file is annotated with additional information like genre, tempo, mood, etc. In our case, we would be interested in the genre label only.
Although there are many open sources for this additional information like Spotify and LastFM, collecting the right data can sometimes be challenging, especially when it comes to labels like the mood of a song. In these cases, it can be a good but also perhaps costly approach to conduct surveys where people are asked “how they feel” when they are listening to a specific song.
Overall, it is crucial to obtain meaningful data since the prediction of our neural network can only be as good as the initial data it learned from (and this is also why data is so valuable these days). To see all the different types metadata used in the music industry, see the article an Overview of Data in the Music Industry.
Moreover, it is also important that the collected data is equally distributed, which means that we want approximately the same amount of, for example, Pop, Rock, and Metal songs in our music dataset.
After collecting a very well labeled and equally distributed dataset, we can proceed with step 2: pre-processing the audio data.
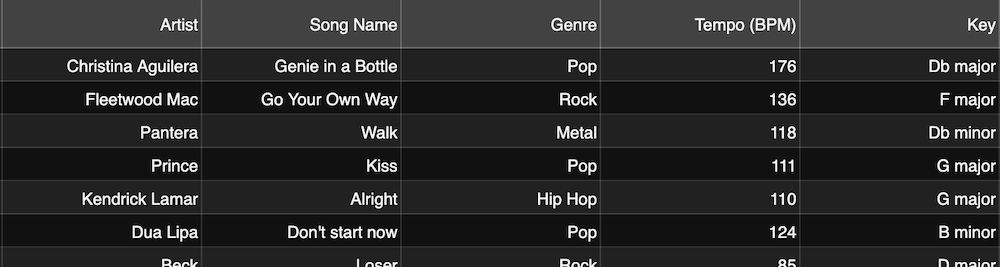
A screenshot from a data collection music database
There are many ways how we can deal with audio data in the scope of music neural networks, but one of the most commonly used approaches is to turn the audio data into “images”, so-called spectrograms. This might sound strange and counterintuitive at first, but it will make sense in a bit.
First of all, a spectrogram is the visual representation of the audio data, more precisely: it shows how the spectrum of frequencies that the audio data contains varies with time. Obtaining the spectrogram of a song is usually the most computationally intensive step, but it will be worth the effort. Spectrograms are essentially data visualizations – you can read about different types of music data visualizations here.
Since great successes were achieved in the fields of computer vision over the last decade using AI and machine learning (face recognition is just one of the many notable examples), it seems natural to take advantage of the accomplishments in computer vision and apply them to our case of AI audio analysis.
That’s why we want to turn our audio data into images. By utilizing computer vision methods, our neural network can “look” at the spectrograms and try to identify patterns there.
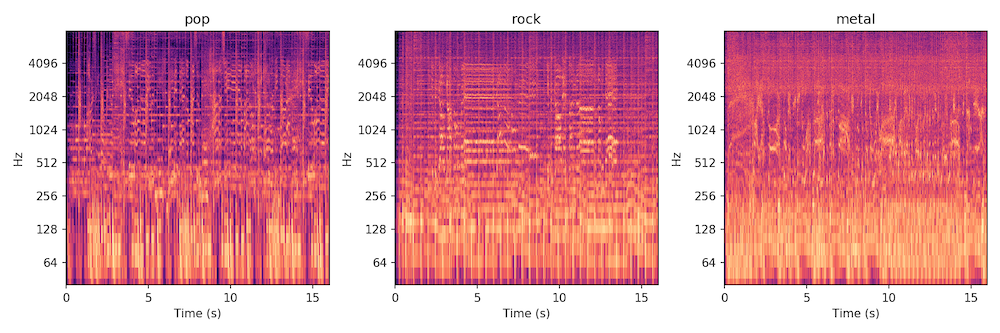
Spectrograms from left to right: Christina Aguilera, Fleetwood Mac, Pantera
Now that we have converted the songs in our database into spectrograms, it is time for our neural network to actually learn how to tell different genres apart.
Speaking of learning: the process of learning is also called training. In our example, the neural network in music will be trained to perform the specific task of predicting the genre of a song.
To do so, we need to split our dataset into two subsets: a training dataset and a test dataset. This means that the network will be only trained on the training dataset. This separation is crucial for the evaluation of the network’s performance later on, but more on that in step 4.
So far, we haven’t talked about how our music neural network will actually look like. There are many different forms of neural network architectures available, but for a computer vision task like trying to identify patterns in spectrograms, so-called convolutional neural networks (CNN) are most commonly applied.
Now, we will feed a song in form of a labeled spectrogram into the network, and the network will return a prediction for the genre of this particular song.
At first, our network will be rather bad at predicting the correct genre of a song. For instance, when we feed a Pop song into the network, the network’s prediction might be a metal song. But since we know the correct genre due to the label, we can tell the network how it needs to improve.
We will repeat this process over and over again (this is why we needed so much data in the first place) until the network will perform well on the given task. This process is called supervised learning because there’s a clear goal for the network that it needs to learn.
During the training process, the network will learn which parts of the spectrograms are characteristic of each genre we want to predict.

Example architecture of how a CNN can look like
In the last step, we need to evaluate how good the network will perform on real-world data. This is why we split our dataset into a training dataset and a test dataset before training the network.
To get a reasonable evaluation, the network needs to perform the genre classification task on data it never has seen before, which in this case will be our test dataset. This is truly an exciting moment because now we get an idea of how good (or maybe bad) our network actually performs.
Regarding our example of genre classification, recent research has shown that the accuracy of a CNN architecture (82%) can surpass human accuracy (70%), which is quite impressive. Depending on the specific task, accuracy can be even higher.
But you need to keep in mind: the more subjective the audio analysis scope is (like genre or mood detection), the lower the accuracy will be.
On the plus side: everything we can differentiate with our human ears in music, a machine might distinguish as well. It’s just a matter of the quality of the initial data.
Artificial intelligence, deep learning, and especially neural network architectures can be a great tool to analyze music in any form. Since there are tens of thousands of new songs released every month and music libraries are growing bigger and bigger, music neural networks can be used for automatically labeling songs in your personal music library and finding similar sounding songs. You can see how the library integration is done in detail in the case study on the BPM Supreme music library and this engaging interview video with MySphera.
Cyanite is designed for these tasks, and you can try it for free by clicking the link below.
I want to integrate AI in my service as well – how can I get started?
Please contact us with any questions about our Cyanite AI via mail@cyanite.ai. You can also directly book a web session with Cyanite co-founder Markus here.
If you want to get the first grip on Cyanite’s technology, you can also register for our free web app to analyze music and try similarity searches without any coding needed.